This post, part of an introductory series to Front End Optimisation practice, summarises some of the key aspects covered, and provides a list of further reading and sources of more advanced/ongoing knowledge of this important and continuously evolving field.
Other titles in this blog series are:
- FEO – reports of its death have been much exaggerated [also published in APM Digest] – 22 February 2016
- Introduction to FEO – Tooling Part 1 – 1 March 2016
- Introduction to FEO – Tooling Part 2 – 8 March 2016
- Introduction to FEO – Operations – Process – 15 March 2016
- Introduction to FEO – Granular Analysis Part 1 – 22 March 2016
- Introduction to FEO – Granular analysis Part 2 -29 March 2016
- Introduction to FEO – Granular analysis Part 3 – 5 April 2016
- Introduction to FEO – Edge Case management – 12 April 2016
- Introduction to FEO – Summary, bibliography for further study
Recommendations
A few final thoughts about FEO recommendations
- Link priorities to business drivers – competitive revenue exposure etc
- Live in the real world – what can be changed at economic cost, in realistic timescales
- Beware major effort for marginal improvement
- Seek to deliver a combination of immediate prioritised interventions & ongoing governance/management of objectives – set iterative goals for improvement (unless in crisis mode).
- Suggest triggers for ongoing intervention based on a combination of direct (synthetic monitoring) and indirect (web analytics, RUM) alert flags.
Summary – everything changes, everything stays the same
In conclusion, the rate of change in the variety of end user applications continues to increase. Some aspects may be black boxed as far as monitoring and analysis is concerned – at least, if without access to core systems and code.
However, in the vast majority of cases, every meaningful aspect of an end user transaction will continue to involve visible changes to the GUI. As such, end user performance can continue to be monitored. Network interaction will still be required, even if it’s on a store and forward rather than real-time basis. Together, these provide the basis of Front End analysis and optimisation.
Provided that there is access to developers / the source code, outputting timing metrics via the range of APIs becoming available provides a robust, production-ready richness to analysis of visitor performance experience. These can prompt intervention & provide deep understanding of production performance. The caveats already expressed (monitoring availability, competitors, and performance in low-traffic situations (including pre-production) still apply.
When presented with new challenges to effective practice, the following cascade should prove its worth:
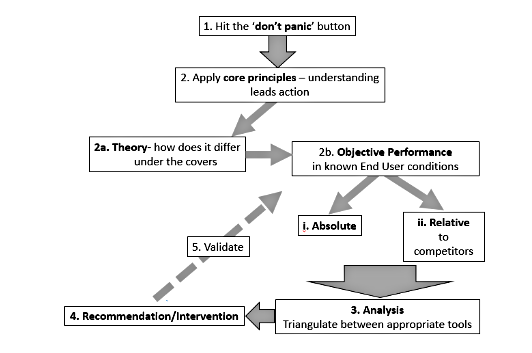
Suggested reading list:
This blog series, although perhaps longer than ideal, has only skated across the surface of the subject. Hopefully, it will provide some practical pointers to effective management / best practice. For those wishing to acquire a deeper understanding (which is certainly recommended). a lot of material exists. The blogosphere, Vendors, independent Consultancies (such as Intechnica [www.intechnica.co.uk]) eBooks, and web performance Meetup groups (such as the excellent London Web Perf MeetUp http://www.meetup.com/London-Web-Performance-Group/ ) are all good sources for keeping abreast of recent developments. For ‘core’ reading, the following are a good start:
- High Performance Websites S Souders Pub O’Reilly 2008 (NB good for core principles, but some of the detail now superseded)
- Even Faster Websites S Souders Pub O’Reilly 2009
- High Performance Browser Networking I Grigorik Pub O’Reilly 2013
- Using WebPagetest Viscomi et al Pub O’Reilly, 2016
- The Art of Application Performance Testing I Molyneaux 2nd Edition 2015 (currently being revised and updated)
